hsqldb 源代码阅读(一)
服务器启动与初始化
以debug模式启动服务器,到如图断点
观察此时的调用堆栈: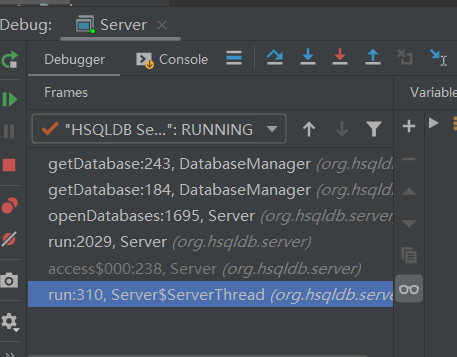
从下至上,为
- run:310, Server$ServerThread(org.hsqldb.server): 这是开启了一个服务器线程
- access$000:238,Server(org.hsqldb.server): 这里应该是实例化一个Server
- run:2029,Server(org.hsqldb,server): 这里是启动这个Server
- openDatabase:1695,Server(org.hsqldb.server): 这里是尝试打开一个初始的database文件
- getDatabase:184,DatabaseManager(org.hsqldb): 这里利用上面打开的database文件实例化一个database对象
- getDatabase:243,DatabaseManager(org.hsqldb): 同上
继续运行,到如图断点:
堆栈新增:getDatabase:259,DatabaseManager(org.hsqldb) 开启初始数据库
继续运行,到如图断点: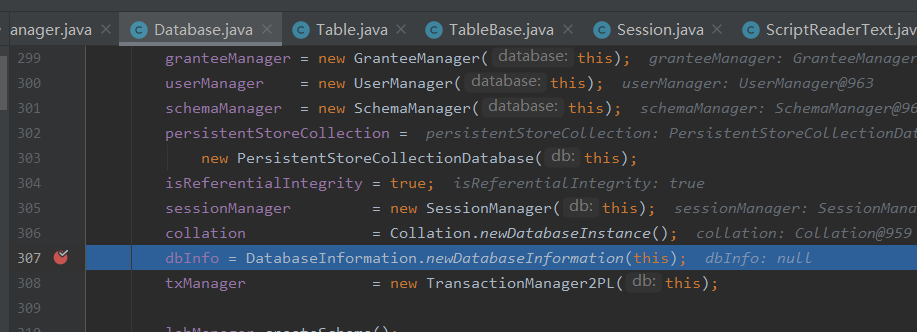
堆栈新增:createObjectStructures:307,Database(org.sqldb) 此处应该是加载初始数据库的元数据
继续运行,到如图断点: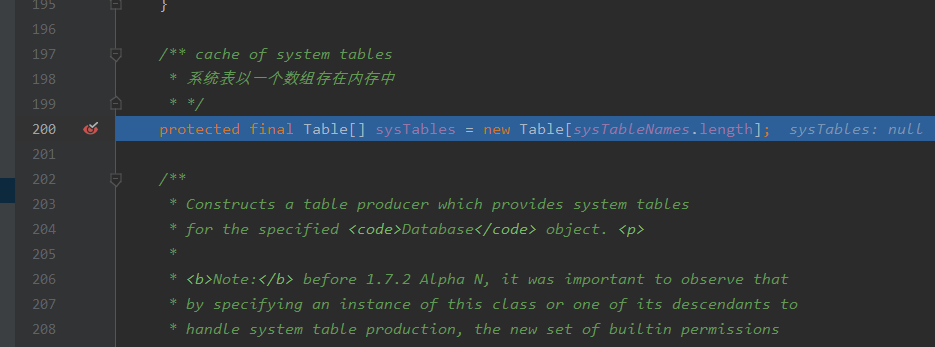
注意,此时堆栈新增了较多数据,我们从下至上来看:
- newDatabaseInformation:338,DatabaseInformation(org.hsqldb.dbinfo): 创建元数据的实例
- newInstance: 423,Constructor(java.lang.reflect): 构建constructoraccessor,也就是数据库文件的slot模型
- newInstance:45,DelegatingConstructorAccessorImpl(sun.reflect): 同上
- newInstance:62,NativeConstructorAccessorImpl(sun.reflect): 同上
- newInstance0:-1,NativeConstructorlmpl(sun.reflect): 同上
:157,DatabaseInformationFull(org.hsqldb.dbinfo): 将元数据与数据库绑定 :200,DatabaseInformationMain(org.hsqldb.dbinfo): 为系统表分配内存,底层数据结构为普通的数组
继续运行,到如图断点: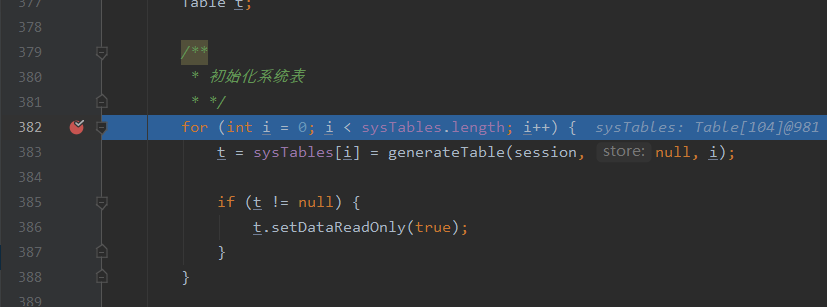
此时的调用栈;
:231,DatabaseInformationMain(org.hsqldb.dbinfo): 和session有关 :382,DatabaseInformationMain(org.hsqldb.dbinfo): 开始初始化系统表
继续运行,到如图断点:
此时调用栈有较大变化,我们从下至上看:
- init:383,DatabaseInformationMain(org.hsqldb.dbinfo): 同上
- generateTable:423,DatabaseInformationFull(org.hsqldb.dbinfo): 同下
- generateTable:305,DatabaseInformationMain(org.hsqldb.dbinfo): 同下
- SYSTEM_BESTROWIDENTIFIER:652,DatabaseInformationMain(org.hsqldb.dbinfo): 建立主键关系约束
- createPrimaryKeyConstraint:1802,Table(org.hsqldb): 同上
- createPrimaryKey:1795,Table(org.hsqldb): 确定哪一个属性是主键
继续运行,到如图断点:
createPrimaryIndex:363,TableBase(org.hsqldb): 准备建立索引表,创建根节点(索引表的底层数据结构是B+树)
继续运行,到如上图368行断点:
就是建立树的过程,把节点逐一地添加到树上
继续运行,你会发现进入到上两个图之间的循环,就是初始化索引表,然后索引表每个节点对应的表初始化一遍。
在循环中,继续运行,到如图断点:
为创建的表添加约束
之和继续循环,23333
继续运行,到如下断点:
这里好像是有关自动提交的,我不确定
继续运行,到如下断点:
堆栈情况:
- processScript:734,Log(org.hsqldb.persist): 从创建的脚本读入session。这里的scr类似文件流。
- readAll:115,ScriptReaderText(org.hsqldb.scriptio): 读入数据定义语言(DDL)
- readDDL:143,ScriptReaderText(org.hsqldb.scriptio): 加载编译过的DDL
- executeCompiledStatement:1419,Session(org.hsqldb): 不明
继续运行,到如上上图断点,进入循环
然后会循环到之前索引表的部分,继续运行,循环结束,如下图:
在这个位置会循环一段时间,应该是逐一地从系统表按顺序获得节点,然后把这个节点插入到B+蜀上(注释中写的是AVL树,B+树其实是AVL树的一种)
继续运行,程序没有反应,可知此时初始化已经完毕,服务器处于监听状态。我们结束Server运行,并以run模式重新运行之,准备下面的对客户端的代码阅读
客户端启动与初始化
以debug模式运行DatabaseManagerSwing,至第一个断点,如下:
我们看看堆栈的变化:
- connect:228,JDBCDriver
- getConnection:277,JDBCDriver
:3434,JDBCConnecion: 以上三步都是通过JDBC连接数据库,因为hsqldb的前端是Java AWT写的,连接到服务器需要通过JDBC - newSession:157,DatabaseManager: 获得database的实例
继续运行,到如下断点:
开启这个数据库(与前面服务器的初始化很像)
继续运行,到如下断点:
之后一段完全是服务器初始化的再现
大段循环之后,客户端进入监听模式,如下图:
数据库创建表,插入/删除数据
在客户端执行
create table personmem(id char(8),name varchar(8),age int,undergraduate boolean,birth_year numeric(4,0),birthdate date,primary key (id));再执行
insert into personmem values ('00000001', 'student1', 22, true, 1995, '1995-01-01');
insert into personmem values ('00000002', 'student2', 22, true, 1995, '1995-01-01');
delete from personmem where id = '00000002';
insert into personmem values ('00000003', 'student3', 22, true, 1995, '1995-01-01');script文件变化如下: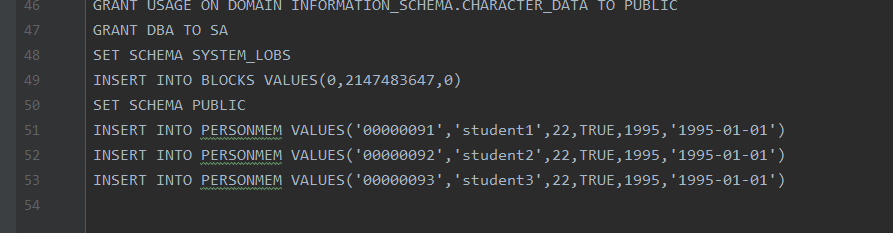
行了,就到这里。
好了,我又回来了
现在我们研究cached table 在底层的存储机制
我们观察test.log,test.script,test.data这三个文件
首先,把之前实验的personmem删掉
drop table personmem然后,在客户端进行以下输入:
create cached table personcache(id char(8),name varchar(8),age int,undergraduate boolean,birth_year numeric(4,0),birthdate date,primary key (id));
insert into personcache values ('00000001', 'student1', 22, true, 1995, '1995-01-01');
insert into personcache values ('00000002', 'student2', 22, true, 1995, '1995-01-01');
delete from personcache where id = '00000002';
insert into personcache values ('00000003', 'student3', 22, true, 1995, '1995-01-01');看到,log文件变化如下:
注意,这里没有设置检查点,所以log文件所有的变化都按照时间被显示出来
设置检查点,输入checkpoint .log文件清空, .script文件记录数据,生成.data文件:
.script文件:
.data文件:
我们可以发现,这里对于永久数据的写入采取了“懒惰”策略,即关于先被插入,后被删除的student2的数据没有在.script中出现
下面我们研究一下text table在hsqldb底层的实现
首先,我们把之前的cached table drop掉
drop table personcache设置检查点
checkpoint然后输入如下:
create text table persontext(id char(8),name varchar(8),age int,undergraduate boolean,birth_year numeric(4,0),birthdate date,primary key (id));SET TABLE PUBLIC.persontext SOURCE "persontextdata;fs=|";以上两句要分开输入,否则会报错
.log文件如下:
然后输入以下语句:
insert into persontext values ('00000001', 'student1', 22, true, 1995, '1995-01-01');
insert into persontext values ('00000002', 'student2', 22, true, 1995, '1995-01-01');
delete from persontext where id = '00000002';
insert into persontext values ('00000003', 'student3', 22, true, 1995, '1995-01-01');.log文件如下: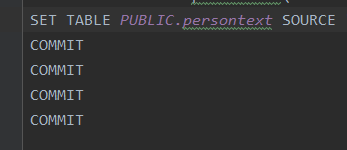
设置检查点后:
.log清空
.script记录元数据: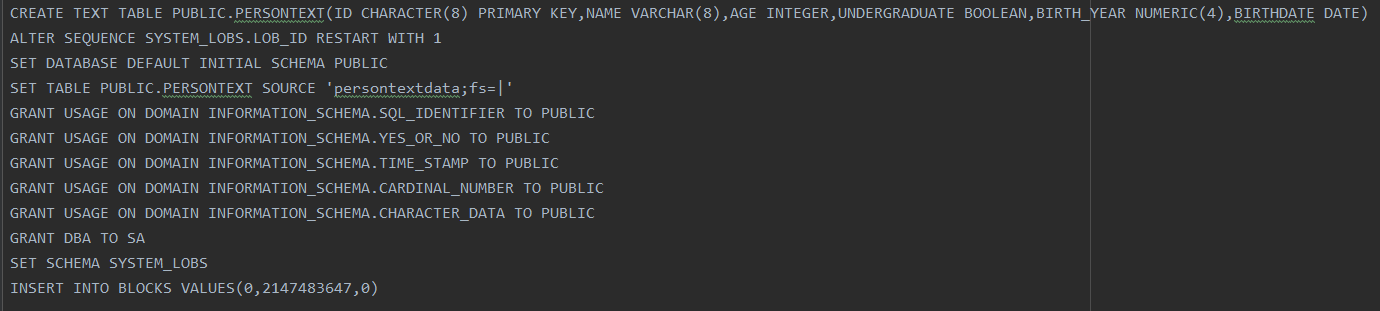
在.log文件的同级目录下多出了一个名为persontextdata的文件:
那么,缓存的替换机制是怎样的?
缓存是以row为单位的。当要提交一个插入的行时,先检查它是否在缓存内。若是,则加入缓存。然后,在缓存中把这个row标记为已经读入主存,以免重复读入。
缓存的容量如何管理?
两个变量exceedsCount与exceedsSize分别记录row条数与总量大小是否超过当前分配的内存限制。如果超了,逐一地增加分配的单元。更新之后,检查二者是否有为0的,如果有,就把这块内存清除(相当于垃圾回收)
Cached/Text Table 增删改数据时外存文件的变化?
- Cached Table无论如何操作,都不会对外存文件有影响
- Text Table只有在设置检查点后,才会写入外存文件,而且写入的是当前的状态,不记录插入或删除的历史。



